Sentiment Analysis on Yelp Reviews
I was looking for public datasets to explore the other day, and I ran into Yelp’s dataset from the Yelp Dataset Challenge. After poking around the data, I realized that it was a treasure trove of data for local businesses – it had around 2.4GB of data and invaluable information ranging from details like location and opening hours of the businesses, to user reviews about service and quality of food.
There are five different datasets:
-
yelp_academic_dataset_businesscontains details about businesses such as opening and closing hours, location, categories, number of reviews, ratings, as well as other attributes ranging from if it takes reservations to if it would be considered ‘hipster’. -
yelp_academic_dataset_checkincontains all the check-in information at businesses. -
yelp_academic_dataset_reviewcontains the reviews for all the businesses, as well as the number of stars associated with the review. It also contains information on whether the review was rated as ‘funny’, ‘useful’ or ‘cool’. -
yelp_academic_dataset_tipcontains the user provided tips for the businesses, as well as the number of likes the tip received. -
yelp_academic_dataset_useris the user information dataset. It contains information such as how many votes the user got, the number of reviews the user wrote, as well as other information like friends, average ratings and so on.
That is a lot of data. I’m getting excited just by the possibility of exploring and learning from all this information. I thought I’d start off by doing something relatively simple - a sentiment analysis on Yelp reviews by training a multinomial naive Bayes classifier.
What is Sentiment Analysis?
Sentiment analysis is ‘the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer’s attitude towards a particular topic, product, etc., is positive, negative, or neutral.’
Sentiment analysis is often used by businesses to analyze general opinion on social media in an attempt to answer questions like
- How are consumers reacting to our competitor’s product?
- What do customers think of the latest addition to our menu?
It provides a more objective quantification to business intelligence, allowing businesses to gather feedback about their services and improve them iteratively. But how we can leverage Yelp reviews to perform this analysis?
Breaking Apart the Reviews Dataset
The review dataset contains the following attributes – type, business_id, user_id, stars, text, date and votes. The only information we need to perform the sentiment analysis is the review and its corresponding rating, and so we can ignore the rest of the attributes. The review provides the text to create our features, and the stars give us a numeric tag for these features.
Let’s start off by reading the data and processing it into a pandas dataframe:
import pandas as pd
with open('yelp_academic_dataset_review.json', 'r') as f:
data = f.readlines()
data = map(lambda x: x.rstrip(), data)
data_json_str = "[" + ','.join(data) + "]"
df = pd.read_json(data_json_str)
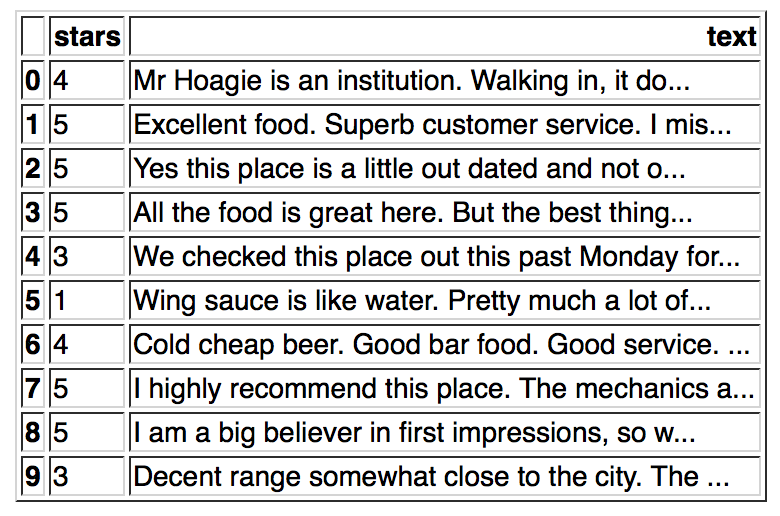
df[['stars','text']].head(10)This should output the first ten entries of the dataset, displaying only the stars and text columns.
Preparing the Data
In machine learning, we usually have a training set and a testing set. The training set is used to train your classifier or model, and improve its ability to make predictions. The testing set is used to objectively measure how well the classifier performs by comparing its output with known results.
Note that if you run len(df.index), you’ll realize that there are 2,225,213 rows in your data frame. That’s great, but processing all of these reviews can take hours or even days, depending on how powerful your machine is. In this tutorial, we’re going to train our classifier with 2000 reviews for our training set, and 2000 for our testing set.
Let’s set up the training and testing sets.
# Generate training data
train_labels = []
train_data = df['text'].head(2000).tolist()
for n in df['stars'].head(2000).as_matrix():
res = 'pos' if n > 3 else 'neg'
train_labels.append(res)
# Generate testing data
test_labels = []
test_data = df['text'].tail(2000).tolist()
for n in df['stars'].tail(2000).as_matrix():
res = 'pos' if n > 3 else 'neg'
test_labels.append(res)The train_data and test_data contain the text of the reviews while the train_labels and test_labels contain their corresponding categories. If the review has more than three stars, we label it as positive sentiment, or pos. If the review has three or fewer stars, we label it as negative sentiment, or neg.
Building Features
In classification, items are represented by their features. In the case of classifying Yelp reviews, our features will be the words that make up the reviews. We use a ‘bag of words’ representation, where we build a dictionary using the words from the set and count the number of occurrences of each word. The scikit-learn library has several vectorizers to translate a document to feature vectors. The CountVectorizer is a handy tool that helps us build up a dictionary of features.
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
train_counts = count_vect.fit_transform(train_data)Having the occurrences of each feature is great, but knowing their frequencies within a document is even more insightful. For example, knowing that a word occurs a hundred times in a short document is more insightful than knowing it occurs the same number of times in a much longer document. We can also downscale the weights for common words that appear in multiple documents and are therefore less informative. TF-IDF, or term frequency-inverse document frequency, is a common way to the tag the words with the right weights by looking at the frequency of their occurrence.
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
train_tfidf = tfidf_transformer.fit_transform(train_counts)Once we have all the weighted features, the next step is to start training the classifier.
Training the classifier
The next step is to actually perform the sentiment analysis with this data. There are many ways you can do this, but one of the most suitable and common ways to do this is to use a multinomial naive Bayes classifier, which applies Bayes’ theorem with the ‘naive’ assumption of independence between every pair of features to a multinomially distributed dataset.
In scikit-learn, training a multinomial naive Bayes classifier is as simple as a single line of code.
clf = MultinomialNB().fit(train_tfidf, train_labels)This fits our data using the categories we labeled the reviews with. We now have a trained classifier!
Testing our Performance
Remember that testing set we created earlier? It’s time to put our classifier to the test using that set.
test_counts = count_vect.transform(test_data)
test_tfidf = tfidf_transformer.transform(test_counts)
predicted = clf.predict(test_tfidf)
print('%.1f%%' % (np.mean(predicted == test_labels) * 100))
>> '89.5%'We’re using the classifier that we training to predict what the sentiment of the reviews in the test data is, and comparing that to the actual sentiment that we labelled them as at the start of this tutorial. Turns out that the classifier is correct 89.5% of the time, which isn’t too bad for a naive Bayes classifier.
You can also test the classifier you just trained on any text to see how it performs.
docs = ['this is an awesome review', 'this is a terrible review']
counts = count_vect.transform(docs)
tfidf = tfidf_transformer.transform(counts)
predicted = clf.predict(tfidf)
for doc, category in zip(docs, predicted):
print('%r => %s' % (doc, category))
>> 'this is an awesome review' => pos
>> 'this is a terrible review' => negWhat’s Next?
Training a classifier is awesome, but what’s even more cool is thinking about the possibilities you can derive from performing sentiment analysis on a dataset to answer questions or derive insights. Here are some examples of questions you can ask yourself:
- Are customers more likely to give positive reviews during breakfast, lunch or dinner?
- Is there a correlation between how many reviews a business has, and how positive its reviews are?
- Does the location of a business affect how popular it is?
In the next blog post, I’ll be answering some of these questions and deriving some interesting insights from the Yelp dataset using the trained classifier.